Last week, during my complex networks winter school, I installed the spark to my Mac. It is a very easy process but there is an error that I want to share.
Firstly, to introduce Spark, it is an engine for large scale data processing. Big data is an example for that. You can code in R, SQL, Python, Scala or Java. Our reason to install Spark was to check GraphX. GraphX is an embedded graph processing framework that is built on the top of Apache Spark.
The main property of GraphX is that data tables and graphs can be used interchangeably. In other words, at any time point, a table can be threaten as a vertex of the graph.
There is two collection which is vertex and edge collection. Mapping and reduce operations are done and made of stages. The drawback is the memory. It has a history preserving method to ignore recomputation of previously done computations.

Ok. So for the installation,
Download the source from Spark.
Ensure Java Home is set.

To set

Then build it with by executing make_distribution.sh
During build operation I came up with this error.
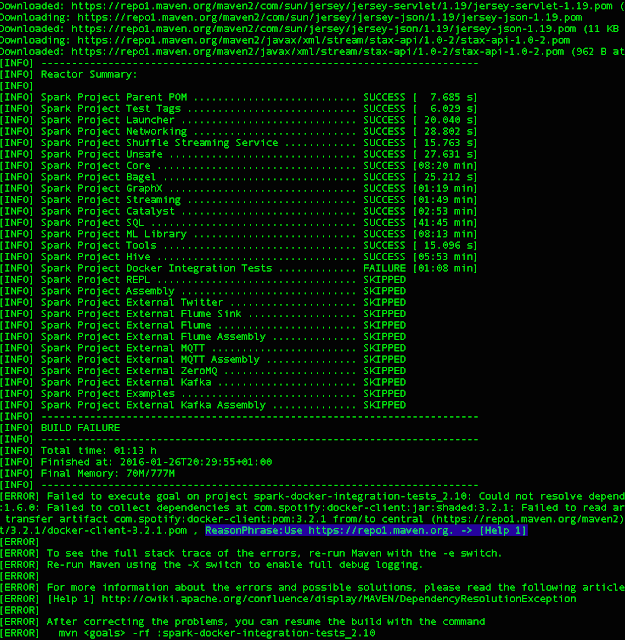
. Then my professor suggested me to build it with a reliable internet connection and Voila! It works. So, since the build operation takes quite a long time, you can take into account that the connection can cause problem. Firstly, to introduce Spark, it is an engine for large scale data processing. Big data is an example for that. You can code in R, SQL, Python, Scala or Java. Our reason to install Spark was to check GraphX. GraphX is an embedded graph processing framework that is built on the top of Apache Spark.
The main property of GraphX is that data tables and graphs can be used interchangeably. In other words, at any time point, a table can be threaten as a vertex of the graph.
There is two collection which is vertex and edge collection. Mapping and reduce operations are done and made of stages. The drawback is the memory. It has a history preserving method to ignore recomputation of previously done computations.
Ok. So for the installation,
Download the source from Spark.
Ensure Java Home is set.
To set
Then build it with by executing make_distribution.sh
During build operation I came up with this error.

There are some proposed solutions in StackOverflow.
Each suggests to modify pom.xml with different repository url from repo.maven to repo1.maven. But my referenced repository was already repo1.maven
So, I changed repo1 url to
After getting build success message ,
Ensure localhost keyword is exist in the conf/slaves file.
Lastly start your cluster by executing . / start-all.sh which is located under /sbin folder.
The system will start the master and worker.
The web interface must be available at http://localhost:8080

Then the second issue to me, during execution, because previously I set an SSH rsa_id. System requested me to type the password.
SSH keys provide a secure way of logging into a server compare to password login itself.
For that, you can what you can do is ;
You can follow the instructions in this website,
Author included the rationale of the commands nicely. I like it.



Good Luck :)









{kind=link}
No comments:
Post a Comment